Factor has good support for implementing mini-languages as libraries. In this post I'll describe the general techniques and look at some specific examples. I don't claim any of this is original research -- Lisp and Forth programmers have been doing DSLs for decades, and recently the Ruby, Haskell and even Java communities are discovering some of these concepts and adding a few of their own to the mix. However, I believe Factor brings some interesting incremental improvements to the table, and the specific combination of capabilities found in Factor is unique.
Preliminaries
How does one embed a mini-language in Factor? Let us look at what goes on when a source file is parsed:
- The parser reads the input program. This consists of definitions and top-level forms. The parser constructs syntax trees, and adds definitions to the dictionary. The result of parsing is the set of top-level forms in the file.
- The compiler is run with all changed definitions. The compiler essentially takes syntax trees as input, and produces machine code as output. Once the compiler finishes compiling the new definitions, they are added to the VM's code heap and may be executed.
- The top level forms in the file are run, if any.
In Factor, all of these stages are extensible. Note that all of this happens when the source file is loaded into memory -- Factor is biased towards compile-time meta-programming.
Extending the parser with parsing words
Parsing words which execute at parse time can be defined. Parsing words can take over the parser entirely and parse custom syntax. All of Factor's standard syntax, such as
: for defining words and
[ for reading a quotation, is actually parsing words defined in the
syntax vocabulary. Commonly-used libraries such as
memoize and
specialized-arrays add their own parsing words for custom definitions and data types. These don't qualify as domain-specific languages since they're too trivial, but they're very useful.
Homoiconic syntax
In most mainstream languages, the data types found in the syntax tree are quite different from the data types you operate on at runtime. For example, consider the following Java program:
if(x < 3) { return x + 3; } else { return foo(x); }This might parse into something like
IfNode(
condition: LessThan(Identifier(x),Integer(3))
trueBranch: ReturnNode(Add(Identifier(x),Integer(3)))
falseBranch: ReturnNode(MethodCall(foo,Identifier(x)))
)
You cannot work with an "if node" in your program, the identifier
x does not exist at runtime, and so on.
In Factor and Lisp, the parser constructs objects such as strings, numbers and lists directly, and identifiers (known as symbols in Lisp, and words in Factor) are first-class types. Consider the following Factor code,
x 3 < [ x 3 + ] [ x foo ] if
This parses as a quotation of 6 elements,
- The word
x - The integer 3
- The word
< - A quotation with three elements,
x, 3, and + - A quotation with two elements,
x, and foo - The word
if
An array literal, like
{ 1 2 3 }, parses as an array of three integers; not an AST node representing an array with three child AST nodes representing integers.
The flipside of homoiconic syntax is being able to print out (almost) any data in a form that can be parsed back in; in Factor, the
. word does this.
What homoiconic syntax gives you as a library author is the ability to write mini-languages without writing a parser. Since you can input almost any data type wth literal syntax, you can program your mini-language in parse trees directly. The mini-language can process nested arrays, quotations, tuples and words instead of parsing a string representation first.
Compile-time macros
All of Factor's data types, including quotations and words, can be constructed at runtime. Factor also supports
compile-time macros in the Lisp sense, but unlike Lisp where they are used to prevent evaluation, a Factor macro is called just like an ordinary word, except the parameters have to be compile-time literals. The macro evaluates to a quotation, and the quotation is compiled in place of the macro call.
Everything that can be done with macros can also be done by constructing quotations at runtime and using
call( -- macros just provide a speed boost.
Parsing word-based DSLs
Many DSLs have a parsing word as their main entry point. The parsing word either takes over the parser completely to parse custom syntax, or it defines some new words and then lets the main parser take over again.
Local variables
A common misconception among people taking a casual look at Factor is that it doesn't offer any form of lexical scoping or named values at all. For example, Reg Braithwaite authoritatively states on
his weblog:
the Factor programming language imposes a single, constraining set of rules on the programmer: programmers switching to Factor must relinquish their local variables to gain Factor’s higher-order programming power.
In fact, Factor supports lexically scoped local variables via the
locals vocabulary. and this library is used throughout the codebase. It looks like in a default image, about 1% of all words use lexical variables.
The locals vocabulary implements a set of parsing words which augment the standard defining words. For example,
:: reads a word definition where input arguments are stored in local variables, instead of being on the stack:
:: lerp ( a b c -- d )
a c *
b 1 c - *
+ ;
The locals vocabulary also supports "let" statements, lambdas with full lexical closure semantics, and mutable variables. The locals vocabulary compiles lexical variable usage down to stack shuffling, and
curry calls (for constructing quotations that close over a variable). This makes it quite efficient, especially since in many cases the Factor compiler can eliminate the closure construction using escape analysis. The choice of whether or not to use locals is one that can be made purely on a stylistic basis, since it has very little effect on performance.
Parsing expression grammars
Parsing expression grammars describe a certain class of languages, as well as a formalism for parsing these languages.
Chris Double implemented a PEG library in Factor. The
peg vocabulary offers a combinator-style interface for constructing parsers, and
peg.ebnf builds on top of this and defines a declarative syntax for specifying parsers.
A simple example of a PEG grammar can be found in Chris Double's
peg.pl0 vocabulary. More elaborate examples can be found in
peg.javascript (JavaScript parser by Chris Double) and
smalltalk.parser (Smalltalk parser by me).
One downside of PEGs is that they have some performance problems; the standard formulation has exponential runtime in the worst case, and the "Packrat" variant that Factor uses runs in linear time but also linear space. For heavy-duty parsing, it appears as if LL and LR parsers are best, and it would be nice if Factor had an implementation of such a parser generator.
However, PEGs are still useful for simple parsing tasks and prototyping. They are used throughout the Factor codebase for many things, including but not limited to:
PEGs can also be used in conjunction with parsing words to embed source code written with custom grammars in Factor source files directly. The next DSL is an example of that.
Infix expressions
Philipp Brüschweiler's
infix vocabulary defines a parsing word which parses an infix math expression using PEGs. The result is then compiled down to
locals, which in turn compile down to stack code.
Here is a word which solves a quadratic equation
ax^2 + bx + c = 0 using the quadratic formula. Infix expressions can only return one value, so this word computes the first root only:
USING: infix locals ;
:: solve-quadratic ( a b c -- r )
[infix (-b + sqrt(b*b-4*a*c))/2*a infix] ;
Note that we're using two mini-languages here;
:: begins a definition with named parameters stored in local variables, and
[infix parses an infix expression which can access these local variables.
XML literals
Daniel Ehrenberg's XML library defines a convenient syntax for constructing XML documents. Dan describes it in detail in
a blog post, with plenty of examples, so I won't repeat it here. The neat thing here is that by adding a pair of parsing words,
[XML and
<XML, he was able to integrate XML snippets into Factor, with parse-time well-formedness checking, no less.
Dan's XML library is now used throughout the Factor codebase, particularly in the web framework, for both parsing and generating XML. For example, the
concatenative.org wiki uses a markup language called "farkup". The
farkup markup language, developed by Dan,
Doug Coleman and myself, makes heavy use of XML literals. Farkup is implemented by first parsing the markup into an abstract syntax tree, and then converting this to HTML using a recursive tree walk that builds XML literals. We avoid constructing XML and HTML through raw string concatenation; instead we use XML literals everywhere now. This results in
cleaner, more secure code.
Compare the design of our farkup library with
markdown.py used by
reddit.com. The latter is implemented with a series of regular expression hacks and lots of ad-hoc string processing which attempts to produce something resembling HTML in the end. New markup injection attacks are found all the time; there was a particularly clever one involving a JavaScript worm that knocked reddit right down a few days ago. I don't claim that Farkup is 100% secure by any means, and certainly it has had an order of magnitude less testing, but without a doubt centralizing XHTML generation makes it much easier to audit and identify potential injection problems.
C library interface
Our C library interface (or FFI) was quite low-level initially but after a ton of work by Alex Chapman, Joe Groff, and myself, it has quite a DSLish flavor. C library bindings resemble C header files on mushrooms. Here is a taste:
TYPEDEF: int cairo_bool_t
CONSTANT: CAIRO_CONTENT_COLOR HEX: 1000
CONSTANT: CAIRO_CONTENT_ALPHA HEX: 2000
CONSTANT: CAIRO_CONTENT_COLOR_ALPHA HEX: 3000
STRUCT: cairo_matrix_t
{ xx double }
{ yx double }
{ xy double }
{ yy double }
{ x0 double }
{ y0 double } ;
FUNCTION: void
cairo_transform ( cairo_t* cr, cairo_matrix_t* matrix ) ;
The Factor compiler generates stubs for calling C functions on the fly from these declarative descriptions; there is no C code generator and no dependency on a C compiler. In fact, C library bindings are so easy to write that for many contributors, it is their first project in Factor. When
Doug Coleman first got involved in Factor, he began by writing a PostgreSQL binding, followed by an implementation of the MD5 checksum. Both libraries have been heavily worked on since then are still in use.
For complete examples of FFI usage, check out any of the following:
There are many more usages of the FFI of course. Since Factor has a minimal VM, all I/O, graphics and interaction with the outside world in general is done with the FFI. Search the Factor source tree for source files that use the
alien.syntax vocabulary.
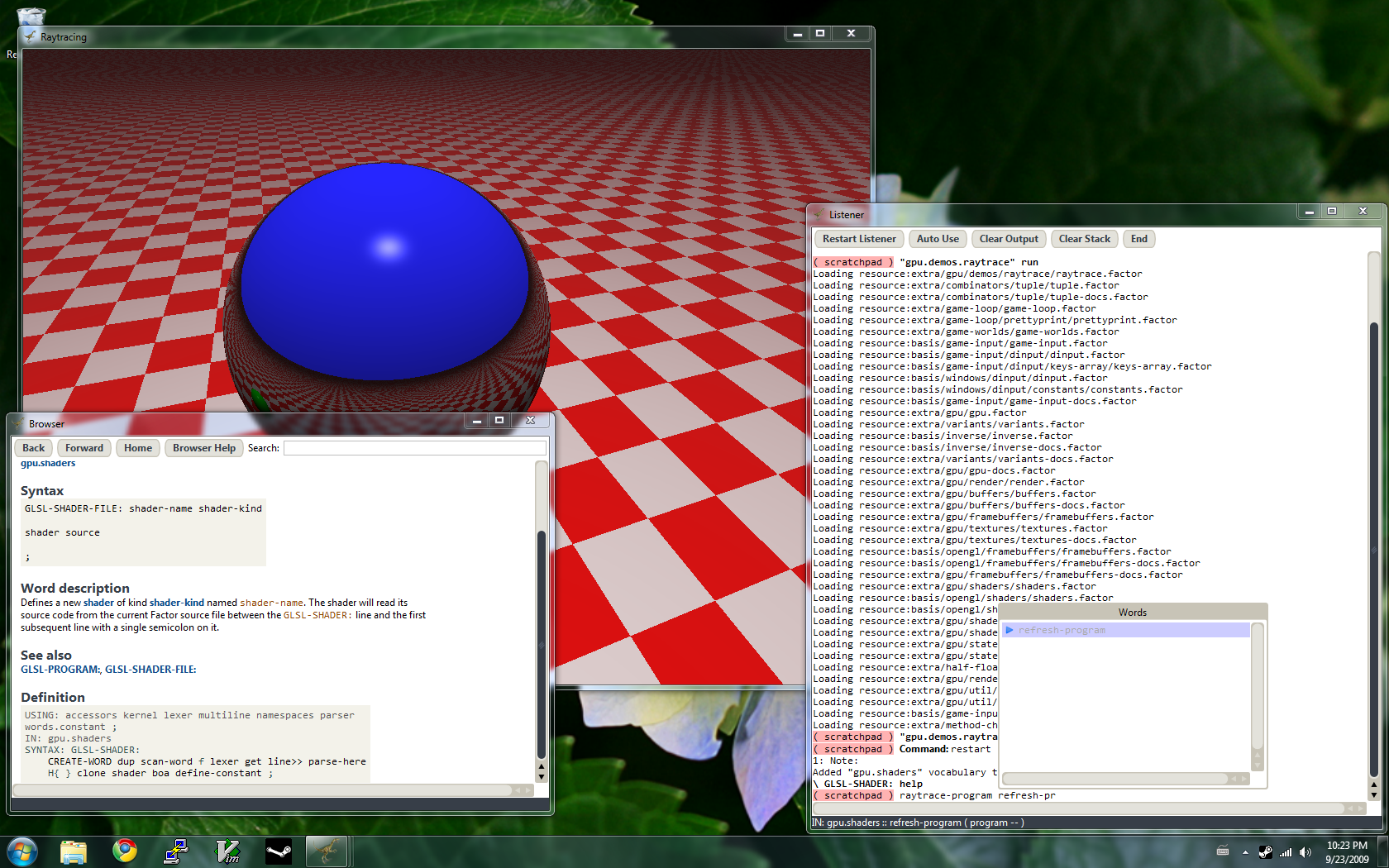
GPU shaders
Joe Groff cooked up a nice DSL for passing uniform parameters to pixel and vertex shaders. In his
blog post, Joe writes:
The library makes it easy to load and interactively update shaders, define binary formats for GPU vertex buffers, and feed parameters to shader code using Factor objects.
Here is a snippet from the
gpu.demos.raytrace demo:
GLSL-SHADER-FILE: raytrace-vertex-shader vertex-shader "raytrace.v.glsl"
GLSL-SHADER-FILE: raytrace-fragment-shader fragment-shader "raytrace.f.glsl"
GLSL-PROGRAM: raytrace-program
raytrace-vertex-shader raytrace-fragment-shader ;
UNIFORM-TUPLE: sphere-uniforms
{ "center" vec3-uniform f }
{ "radius" float-uniform f }
{ "color" vec4-uniform f } ;
UNIFORM-TUPLE: raytrace-uniforms
{ "mv-inv-matrix" mat4-uniform f }
{ "fov" vec2-uniform f }
{ "spheres" sphere-uniforms 4 }
{ "floor-height" float-uniform f }
{ "floor-color" vec4-uniform 2 }
{ "background-color" vec4-uniform f }
{ "light-direction" vec3-uniform f } ;
The
GLSL-SHADER-FILE: parsing word tells Factor to load a GLSL shader program. The GPU framework automatically checks the file for modification, reloading it if necessary.
The
UNIFORM-TUPLE: parsing word defines a new tuple class, together with methods which destructure the tuple and bind textures and uniform parameters. Uniform parameters are named as such because they define values which remain constant at every pixel or vertex that the shader program operates on.
Instruction definitions in the compiler
This one is rather obscure and technical, but it has made my job easier over the last few weeks.
I blogged about it already.
Other examples
The next set of DSLs don't involve parsing words as much as just clever tricks with evaluation semantics.
Inverse
Daniel Ehrenberg's inverse library implements a form of pattern matching by computing the inverse of a Factor quotation. The fundamental combinator,
undo, takes a Factor quotation, and executes it "in reverse". So if there is a constructed tuple on the stack, undoing the constructor will leave the slots on the stack. If the top of the stack doesn't match anything that the constructor could've produced, then the inverse fails, and pattern matching can move on to the next clause. This library works by introspecting quotations and the words they contain. Dan gives many details and examples in
his paper on inverse.
Help system
Factor's help system uses an s-expression-like markup language. Help markup is parsed by the Factor parser without any special parsing words. A markup element is an array where the first element is a distinguished word and the rest are parameters. Examples:
"This is " { $strong "not" } " a good idea"
{ $list
"milk"
"flour"
"eggs"
}
{ $link "help" }This markup is rendered either directly on the Factor UI (like in this
screenshot) or via HTML, as on the
docs.factorcode.org site.
The nice thing about being able to view help in the UI environment is the sheer interactive nature of it. Unlike something like javadoc, there is no offline processing step which takes your source file and spits out rendered markup. You just load a vocabulary into your Factor instance and the documentation is available instantly. You can look at the help for any documented word by simply typing something like
\ append help
in the UI listener. While working on your own vocabulary, you can reload changes to the documentation and see them appear instantly in the UI's help browser.
Finally, it is worth mentioning that because of the high degree of semantic information encoded in documentation, many kinds of mistakes can be caught in an automated fashion. The
help lint tool finds inconsistencies between the actual parameters that a function takes, and the documented parameters, as well as code examples that don't evaluate to what the documentation claims they evaluate to, and a few other things.
You won't find a lot of comments in Factor source, because the help system is much more useful. Instead of plain-text comments that can go out of date, why not have rich text with hyperlinks and semantic information?
For examples of help markup, look at any file whose name ends with
-docs.factor in the Factor source tree. There are plenty.
x86 and PowerPC assemblers
I put this one last since its not really a DSL at all, just a nice API. The lowest level of Factor's compiler generates machine code from the compiler's intermediate form in a CPU-specific way. The CPU backends for x86 and PowerPC use the
cpu.x86.assembler and
cpu.ppc.assembler vocabularies for this, respectively. The way the assemblers work is that they define a set of words corresponding to CPU instructions. Instruction words takes operands from the stack -- which are objects representing registers, immediate values, and in the case of the x86, addressing modes. They then combine the operands and the instruction into a binary opcode, and add it to a byte vector stored in a dynamically-scoped variable. So instead of calling methods on, and passing around, an 'assembler object' as you would in say, a JIT coded in C++, you wrap the code generation in a call to Factor's
make word, and simply invoke instruction words therein. The result looks like assembler source, except it is postfix. Here is an x86 example:
[
EAX ECX ADD
XMM0 XMM1 HEX: ff SHUFPS
AL 7 OR
RAX 15 [+] RDI MOV
] B{ } make .
When evaluated, the above will print out the following;
B{ 1 200 15 198 193 255 131 200 7 72 137 120 15 }Of course,
B{ is the homoiconic syntax for a byte array. Note the way indirect memory operands are constructed; first, we push the register (
RAX) then the displacement (here the constant 15, but register displacement is supported by x86 too). Then we call a word
[+] which constructs an object representing the addressing mode
[RAX+15].
The rationale for choosing this somewhat funny syntax for indirect operands (there is also a
[] word for memory loads without a displacement), rather than some kind of parser hack that allows one to write
[RAX] or
[R14+RDI] directly, is that in reality the compiler only rarely deals with hard-coded register assignments. Instead, the register allocator makes decisions a level above, and passes them to the code generator. Here is a typical compiler code generation template from the
cpu.x86 vocabulary:
M:: x86 %check-nursery ( label temp1 temp2 -- )
temp1 load-zone-ptr
temp2 temp1 cell [+] MOV
temp2 1024 ADD
temp1 temp1 3 cells [+] MOV
temp2 temp1 CMP
label JLE ;
Here, I'm using the locals vocabulary together with the assembler. The
temp1 and
temp2 parameters are registers and
label is, as its name implies, a label to jump to. This snippet generates machine code that checks whether or not the new object allocation area has enough space; if so, it jumps to the label, otherwise it falls through (code to save live registers and call the GC is generated next). The
load-zone-ptr word is like an assembler macro here; it takes a register and generates some more code with it.
The PowerPC assembler is a tad more interesting. Since the x86 instruction set is so complex, with many addressing modes and so on, the x86 assembler is implemented in a rather tedious manner. Obvious duplication is abstracted out. However, there is a lot of case-by-case code for different groups of instructions, with no coherent underlying abstraction allowing the instruction set to be described in a declarative way.
On PowerPC, the situation is better. Since the instruction set is a lot more regular (fixed width instructions, only a few distinct instruction formats, no addressing modes), the PowerPC assembler itself is built using a DSL specifically for describing PowerPC instructions:
D: ADDI 14
D: ADDIC 12
D: ADDIC. 13
D: ADDIS 15
D: CMPI 11
D: CMPLI 10
...
The PowerPC instruction format DSL is defined in the
cpu.ppc.assembler.backend vocabulary, and as a result the
cpu.ppc.assembler vocabulary itself is mostly trivial.
Last words
Usually my blog posts describe recent progress in the Factor implementation, and I tend to write about what I'm working on right now. I'm currently working on code generation for SIMD vector instructions in the Factor compiler. I was going to blog about this instead, but decided not to do it until the SIMD implementation and API settles down some more.
With this post I decided to try something a bit different, and instead just describe an aspect of Factor that interests to me, without any of it being particularly breaking news. If you've been following Factor development closely, there is literally nothing in this post that you would not have seen already, however I figured people who don't track the project so closely might appreciate a general survey like this. I'm also thinking of writing a post describing Factor's various high-level I/O libraries. I'd appreciate any feedback, suggestions and ideas on this matter.





{kind=link}